
機械学習で用いるハイパーパラメータ管理には,主に二つの方法が考えられる.
- argparseを用いてコマンドラインからハイパーパラメータを設定

- 実験ごとにハイパーパラメータをまとめたファイルを作成

ありがちなハイパーパラメータ管理の例
argparseを用いてハイパーパラメータを管理する場合,コマンドラインから直接変更できるのが便利だが,往々にして設定するハイパーパラメータが膨大になる.また,設定ファイルに記述することでハイパーパラメータを管理する場合,ハイパーパラメータの変更の度に設定ファイルを修正しなければならない.
効果的なハイパーパラメータの値を決定したい場合,複数のハイパーパラメータの試行錯誤が面倒であるだけでなく,候補となるハイパーパラメータ数に応じて設定ファイルの修正が生じ,膨大な結果の保存 & 比較が困難になる.
こうした問題点は,Hydra+MLflow(tm)+Optunaにより解決できる.
Hydra+MLflow+Optunaによるハイパーパラメータ管理では
設定したハイパーパラメータをコマンドラインから設定ファイルを直接編集することなく,変更 & 実行することができる.Hydraでは,コマンドラインから変数のグリッドサーチを行うことができ,設定ファイルが増え続ける心配もない.さらに,HydraのOptunaプラグインにより,Optunaの強力なハイパーパラメータ探索機能をコマンドラインから利用することができ,ハイパーパラメータの探索 & 管理がより効果的なものとなる.本稿では,Hydra+MLflowによるハイパーパラメータ管理を紹介し,さらに,Hydraのプラグインを用いたOptunaの導入方法についても説明する.
Hydra
Hydraは,Facebook AI Research が公開しているハイパーパラメータ管理ツールで,ハイパーパラメータを階層立てて構造的にYAMLファイルに記述することができる.さらに,コマンドラインから直接設定値を変更 & 実行したり,ハイパーパラメータのグリッドサーチをコマンドラインから1行で実行することができる.
基本的な使い方
- 管理したいハイパーパラメータをyaml形式でConfigファイルに記述
- 設定したハイパーパラメータを関数にデコレータを渡すことでプログラム内から参照可能
コマンドラインからの値の変更 & 実行
Hydraでは,ハイパーパラメータの値を調整してプログラムを再実行したい場合,コマンドラインからハイパーパラメータの値を直接変更し,プログラムを実行することができる.先の例で,node1を128から64に変更しプログラムを再実行したい場合,コマンドラインで値を直接指定し,変更 & 実行することができる.
ハイパーパラメータのグリッドサーチ
数種類のハイパーパラメータを順に用いて実行したい場合,Configファイルを書き換えることなく,コマンドラインから直接指定することもできる.先の例で,node1を{128, 256},node2を{16, 32}で変更したい場合,以下のようにコマンドラインから指定することができる.指定したハイパーパラメータの組み合わせの数に応じて,実行される.
MLflow
MLflowは機械学習ライフサイクルを実現するオープンソースである.Hydraと組み合わせることにより,ハイパーパラメータの管理・グリッドサーチ・保存・比較が可能になる.本稿では,MLflow Trackingを用いた実験ハイパーパラメータ管理を紹介する.
MLflow Tracking
MLflow Trackingは,機械学習のコードを実行する際のハイパーパラメータのロギング,lossやaccuracyなどのメトリクス,出力ファイルなどの管理を補助するためのAPIを提供する.pipを通してインストールすることができる.
基本的な使い方
MLlowが提供するロギング関数を用いることで,ハイパーパラメータ・メトリックを記録することができる.具体的には,start_run()でrunIDの発行,log_param()でハイパーパラメータの登録,log_metric()でメトリックの記録,log_artifact()で出力されたファイル等の記録をすることができる.
以下のコマンドでローカルサーバー上で記録されたハイパーパラメータの比較ができる.
HydraとMLflowの実装例
HydraとMLflowを組み合わせることで,元のファイルを大きく変更することなく,ハイパーパラメータの管理・変更が実現できる.以下のコードはPyTorchを用いた機械学習モデルにHydraとMLflowを導入した例である.
同様にコマンドラインで直接,複数のハイパーパラメータを指定しグリッドサーチすることができる.
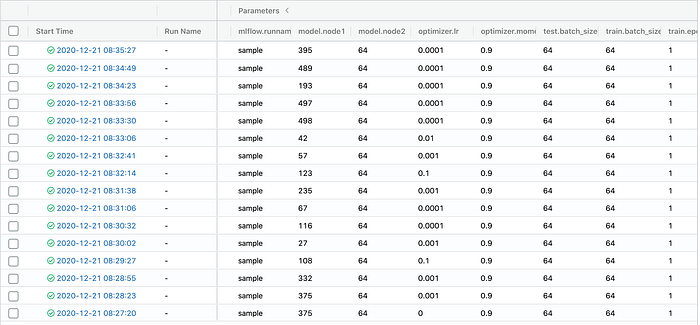
上記のコマンドを実行すると,ローカルサーバー上で以下のような画面が確認できる.全てのハイパーパラメータの組み合わせに対するlossやaccuracyなどの登録したメトリックの結果を容易に比較することができる.

Optunaの導入
Hydra+MLflowによるハイパーパラメータの管理およびグリッドサーチ,全てのハイパーパラメータ組み合わせに対するメトリックの比較を紹介した.Optunaを導入することにより,Hydraによるハイパーパラメータのグリッドサーチだけでなくハイパーパラメータの最適化を実現できる.さらに,Hydraのプラグインを利用することで,Optunaの導入が非常に容易になる.ここからは,Hydra+MLflow+Optunaの組み合わせを具体例とともに紹介する.
Optunaとは
Optunaは,オープンソースのハイパーパラメータ自動最適化フレームワークである.ハイパーパラメータの値に関する試行錯誤を自動化し,優れた性能を発揮するハイパーパラメータ値を自動的に発見することができる.
Hydra+MLflow+Optuna
HydraのOptuna Sweeperプラグインを用いると,Hydraで使用する設定ファイルに最適化したい変数と探索条件を記述するだけで,ハイパーパラメータ最適化を実施することができる.さらに,コマンドラインから直接,最適化される変数と探索条件を変更することができる.Optuna Sweeper プラグインは,pipでインストールすることができる.
Optunaを利用する際の変更点
以下のように,Hydraのデコレータで用いる設定ファイルにOptunaに関する設定を追加で書き込むことで,Optunaの設定は完了する.
さらに,デコレータを渡した関数の返り値を最小化あるいは最大化したい目的変数とする.以下のコードは,デコレータを渡した関数の返り値を,最大化したいaccuracyとした一例である.
以上の変更点のみで,Optunaの導入は完了である.あとは,コマンドラインから最適化したい変数およびその探索範囲を直接指定できる.次のコードは,accuracyを最大化する,optimizerの学習率とモデルのノード数をコマンドラインから探索条件とともに記載した例である.choiceはカテゴリ型の変数に変換されるため,optimizerの4種類の学習率が探索される.また,rangeは整数型の変数に変換されるため,以下の例では,model.node1が[10, 500]の間かつ整数の範囲で探索される.他にも様々な分布に対応しているが,ここでは割愛する.
MLflow上での可視化
当然,Optunaで探索されたハイパーパラメータの値および目的関数の値MLflowで構築したローカルサーバー上で確認することができる.
まとめ
Hydra+MLflow
ハイパーパラメータの管理およびグリッドサーチを実現するHydraと使用されたハイパーパラメータの一元記録および結果の可視化を実現するMLflowを組み合わせることにより,実験ごとに増えていくハイパーパラメータを容易に変更・管理し,さらにGUI上で比較できた.
Hydra+MLflow + Optuna!
上記の組み合わせにOptunaを取り入れることで,Hydraのプラグインを用いてOptunaを容易に導入でき,グリッドサーチだけでなく,さらに詳細なハイパーパラメータの探索を行うことができた.探索されたハイパーパラメータおよび目的変数の値もMLflowにより一元管理・比較できた.
